強化学習をやってみたいから骨組みをつくったり、、、
強化学習を少しかじる
強化学習そういえばやったことないなと思ったので、少しだけかじってみる。
理論的な部分については、作りながら覚える+わざわざ記事にする必要ないので、、、
とはいえ、巷に転がっているのは振り子が落としたイケナイゲームをなんかゴニョっておしまいで、
え?自作はどーするの?ってなったので、今後自作ができるようなSAMPLEを探してみた。
なんかいい感じに纏まっているものないかと検索していたところ、こんなものを発見したので、これに沿ってやってみる。必要あらば適宜加筆を行う
こちらですが、問題定義は以下の様になっています。かなりシンプルですが、癖がありますねw
- 状況:シャワーの温度最適化
- できること:シャワーの温度を1度ずつ変更できる
- シャワーは60秒間で1秒に一回変更できる。

いざ実装
とはいえ、こぴりつつ補足あらば加筆します
実行環境構築
実行環境と強化学習の環境がぶる。。。
今回は特別なものは使いません
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
!pip install tensorflow==2.3.0 # OpenAI gym: 強化学習プラットフォーム !pip install gym !pip install keras # keras を RL(強化学習)で使えるようにするlib !pip install keras-rl2 # 基礎となる環境 from gym import Env # 行動などで用いる変数の定義 from gym.spaces import Discrete, Box #others import numpy as np import random |
環境をつくる
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
# Cutom Env # inherit from openAI Env class ShowEnv(Env): # initialize def __init__(self): # actionの取りうる値の空間 # 0: down, 1: stay, 2: up self.action_space = Discrete(3) # 観測データの取りうる値の空間: # continuous (multiple-value) value. Used for images dataframe self.observation_space = Box(low=np.array([0]), high=np.array([100])) # state: temprature self.state = 38+ random.randint(-1,3) # iteration self.shower_length = 60 def step(self, action): # Apply action # 0 -1 = -1 temperature # 1 -1 = 0 # 2 -1 = 1 temperature self.state += action -1 # Reduce shower length by 1 second self.shower_length -= 1 # Calculate reward # very simple if self.state >=37 and self.state <=39: reward =1 else: reward = -1 # Check if shower is done ( check finish ) if self.shower_length <= 0: done = True else: done = False # Apply temperature noise # Havinng nonise is aid to simulate a real env # but it takes longer self.state += random.randint(-1,1) # Set placeholder for info info = {} # Return step information return self.state, reward, done, info # visualize def render(self): # imfomative # フリコなら振り子が揺れるやつを画面表示できる。 pass # reset env def reset(self): # Reset shower temperature self.state = 38 + random.randint(-3,3) # Reset shower time self.shower_length = 60 return self.state |
報酬定義
今回はかなりシンプルに作っていますが、
実際はどのように報酬を定義するか?は非常に重要です。強化学習はこいつを最大化する方向にしか動いてくれないので、見落としの先には、、、
環境の変化
実際には環境はアクションを受けて変化するのが常。
今回はシンプルに、アクションでは無くてアクション叩くたびになんかしらのノイズを加えてこの状況を再現します
|
1 |
self.state += random.randint(-1,1) |
一応これで環境はできました。自作には上コードの4つの関数は必須だそうです。次に中身を見てみます。
https://github.com/openai/gym/blob/master/gym/core.py
|
1 2 3 4 5 6 7 8 |
# Get first env env = ShowEnv() # temperature example print(env.observation_space.sample()) # ==> [0.12433] # Action example print(env.action_space.sample()) # ==> 0 |
観測のサンプルとアクションのSAMPLEを取得しました。実行毎にことなるはずです.
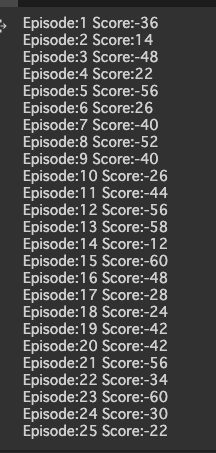
次に、試しに適当に25ループ回してみた。
|
1 2 3 4 5 6 7 8 9 10 11 |
episodes = 25 for episode in range(1, episodes+1): state = env.reset() done = False score = 0 while not done: #env.render() action = env.action_space.sample() n_state, reward, done, info = env.step(action) score+=reward print('Episode:{} Score:{}'.format(episode, score)) |
ここでは、ひたすら
(1)行動を実行し、
(2)observation, reward, done, infoの4value tupleを受領、
(3)累積報酬計算
なので、とくに環境がどうだ!と言って省みることはしませんので25回実行しても、良くなりません。
ちゃんとエージェントを考える。
環境と対にあるのがエージェント。
エージェントの脳みそであるモデルをつくる。一昔前だとこの脳味噌がDNNではなくて、正解データに基づいた勾配法とかを使っている
隠れ1層の単純モデルにしよう
|
1 2 3 4 |
import numpy as np from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Flatten from tensorflow.keras.optimizers import Adam |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# Create Simple DNN def build_model(states, actions): model = Sequential() model.add(Dense(24,activation = 'relu', input_shape=states)) model.add(Dense(24, activation='relu')) model.add(Dense(actions, activation='linear')) #return action return model # create model = build_model( states = env.observation_space.shape, actions = env.action_space.n ) #show summary model.summary() Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_3 (Dense) (None, 24) 48 _________________________________________________________________ dense_4 (Dense) (None, 24) 600 _________________________________________________________________ dense_5 (Dense) (None, 3) 75 ================================================================= Total params: 723 Trainable params: 723 Non-trainable params: 0 _________________________________________________________________ |
モデルをエージェント本体に入れる
rlライブラリから便利なモジュールを入れ込む
|
1 2 3 4 |
#便利なエージェントモジュール from rl.agents import DQNAgent from rl.policy import BoltzmannQPolicy from rl.memory import SequentialMemory |
方策としてBoltzmannQPolicyを用いる。
BoltzmannQPolicyは行動のQ値をソフトマックスにかけて選択する手法。つまりは、-1/0/1のどれが良いのかをQ値をもとに選択してくれる。他にはGreedyQPolicyとか色々あるってのが、実際にコードを見るとわかる
https://github.com/keras-rl/keras-rl/blob/master/rl/policy.py
これによると、自作なら(1)Policyクラスを継承の上で(2)select_acitonメソッドを継承しろと言っている
Experience replay
初めて知ったのだが、強化学習にはExperience replayという最適化手法がある。
過去の経験(=行動とその結果)をサンプリングして学習データとして再利用したりする手法で、時間的に近いと「多分」似た経験だから局所最適解に陥っちゃう。
ってことで、ある程度溜め込んで経験をランダムにピックアップしてミニバッチとして入力させることでうまく行くらしい
今回はSequentialMemoryを使用する
https://github.com/keras-rl/keras-rl/blob/master/rl/memory.py
もう一つクラスが見えますが、これはまたの機会に
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def build_agent(model, actions): policy = BoltzmannQPolicy() memory = SequentialMemory(limit=50000, window_length=1) dqn = DQNAgent(model=model, memory=memory, policy=policy, nb_actions=actions, nb_steps_warmup=10, target_model_update=1e-2) return dqn dqn = build_agent( model = model, actions = env.action_space.n ) dqn.compile(Adam(lr=1e-3), metrics=['mae'])#lossは設定不可 dqn.fit(env, nb_steps=500, visualize=False, verbose=1) |
一気に書いてみた。
compileの部分は最適化手法がいくつか使えるのと、metricがtfと同じように使える。
残念なのはloss関数を定義できない点。
今回はすぐ学習終わらせたいのでepisode=500に設定
Testしてみる
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import rl.callbacks # call back も設定できる class EpisodeLogger(rl.callbacks.Callback): def __init__(self): self.observations = {} self.rewards = {} self.actions = {} def on_episode_begin(self, episode, logs): self.observations[episode] = [] self.rewards[episode] = [] self.actions[episode] = [] def on_step_end(self, step, logs): episode = logs['episode'] self.observations[episode].append(logs['observation']) self.rewards[episode].append(logs['reward']) self.actions[episode].append(logs['action']) cb_ep = EpisodeLogger() scores = dqn.test(env, nb_episodes=10, visualize=False, callbacks=[cb_ep]) print(np.mean(scores.history['episode_reward'])) |
ここにはtensor_callbackみたいなノリでコールバック関数を定義できる。
ちなみに、visualizeはちゃんと環境の法でrenderメソッド定義していないとエラーゲロるので今回はずっとfalse
|
1 2 3 4 5 6 7 |
%matplotlib inline import matplotlib.pyplot as plt for obs in cb_ep.observations.values(): plt.plot(obs) plt.xlabel("step") plt.ylabel("pos") |

凡例つければよかったが、10エピソードの中ではいい感じになっている印象はないですね
まぁちゃんと学習すればよいですが
強化学習ではエージェントの脳味噌はモデル(=DNN)なのんで、
このときのDNNの重みさえ保存してしまえば後で再利用OK
|
1 2 |
dqn.save_weights('dqn_weights.h5f', overwrite=True) # dqn.load_weights('dqn_weights.h5f') |
できた。
こんかい参考にしたsiteたち
- 作りながら学ぶ強化学習 -初歩からPyTorchによる深層強化学習まで
- DQNの理論説明
- Pythonの強化学習ライブラリKeras-RLのパラメータ設定
- DQNの生い立ち + Deep Q-NetworkをChainerで書いた
- 【ここまで分かれば概要を理解できる】強化学習問題の基本的考え方
えーなんか作りたいねーこれつかって。
その前にやっぱり理論をしりたくなる